Why using Mean Squared Error(MSE) cost function for Binary Classification is a bad idea?
14 Nov 2019 · math, binary-classification, mse, loss-functions, deep-learning
This blog was originally published on Medium
Supplementary part of the blog post “Nothing but NumPy: Understanding & Creating Binary Classification Neural Networks with Computational Graphs from Scratch”
There are two reasons why Mean Squared Error (MSE) is a bad choice for binary classification problems:
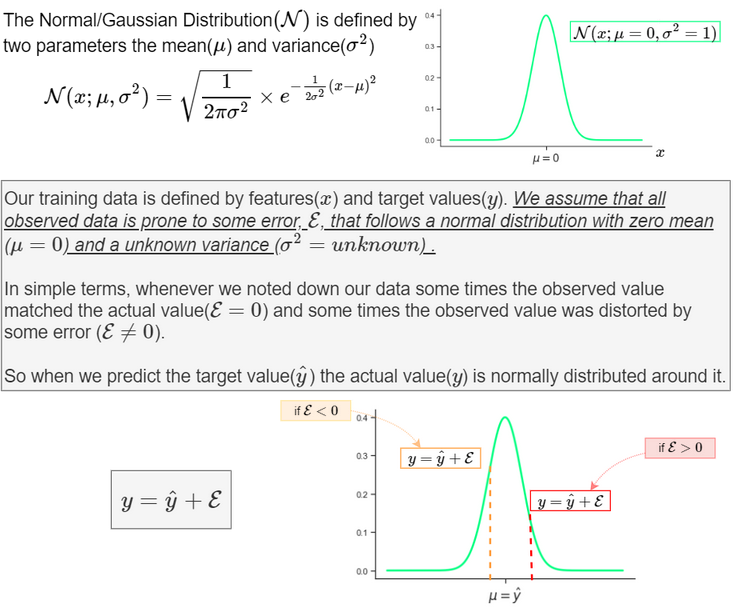
First*, using MSE means that we assume that the underlying data has been generated from a normal distribution (a bell-shaped curve)*. In Bayesian terms this means we assume a Gaussian prior. While in reality, a dataset that can be classified into two categories (i.e binary) is not from a normal distribution but a Bernoulli distribution (Check out the answer to “Where did the Binary Cross-Entropy Loss Function come from?” for more details and also for an intro to maximum likelihood estimation).
If we use maximum likelihood estimation (MLE), assuming that the data is from a normal distribution (a wrong assumption, by the way), we get the MSE as a Cost function for optimizing our model.

Secondly, the MSE function is non-convex for binary classification. In simple terms, if a binary classification model is trained with MSE Cost function, it is not guaranteed to minimize the Cost function. This is because MSE function expects real-valued inputs in range (-∞, ∞), while binary classification models output probabilities in range (0,1) through the sigmoid/logistic function. Let’s visualize:
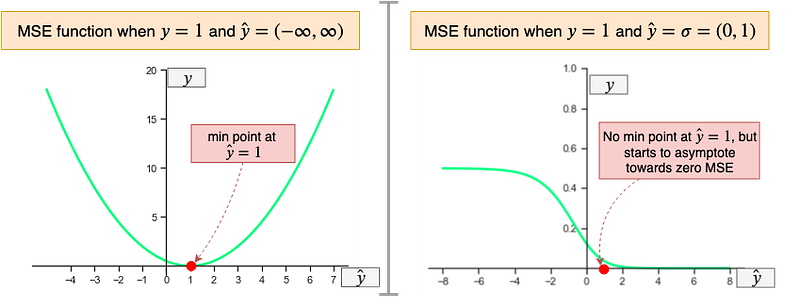
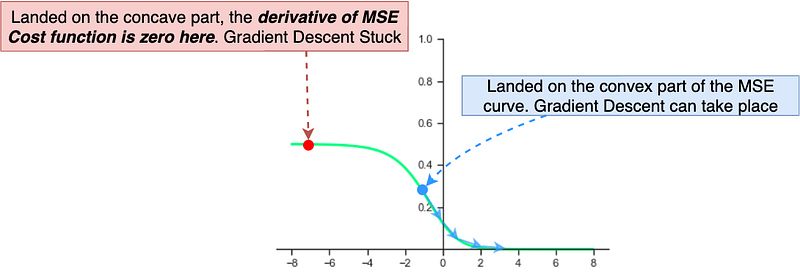
When the MSE function is passed a value that is unbounded a nice U-shaped (convex) curve is the result where there is a clear minimum point at the target value (y). On the other hand, when a bounded value from a Sigmoid function is passed to the MSE function the result is not convex; on one side the function is concave while on the other side the function convex and no clear minimum point. So, if by accident a binary classification neural network is initialized with weights which are large in magnitude such that it lands on the concave part of the MSE Cost function gradient descent will not work and consequently, weights may not update or improve very slowly(try this out in coding section). This is one of the reasons why neural networks should be carefully initialized with small values when training.
On a final note, MSE is a good choice for a Cost function when we are doing Linear Regression (i.e fitting a line through data for extrapolation). In the absence of any knowledge of how the data is distributed assuming normal/gaussian distribution is perfectly reasonable.

For any questions feel free to reach out to me on Twitter @RafayAK and check out the rest of the post on “binary classification”.